Pohodlný vývoj Composer balíčků
Na fóru se Lexi ptal, jak řešit vývoj Composer balíčků. Já vyzkoušel tyhle tři varianty, respektive tyhle 3 jsou podle mě použitelné a hodí se v různých situacích.
Na fóru se Lexi ptal, jak řešit vývoj Composer balíčků. Já vyzkoušel tyhle tři varianty, respektive tyhle 3 jsou podle mě použitelné a hodí se v různých situacích.
Včera se za mnou stavil kamarád s úplatky, že by potřeboval pomoct rozběhat automatické přispívání na Facebook Page. Protože Facebook zase nedávno udělal novou verzi api, tentokrát v2.3, tak spousta návodů jak publikovat na stránky jménem stránky je trošku obsolete a hlavně, ještě nikdo nenapsal návod pro Kdyby/Facebook :) Tak jsem na to s ním sedl, opravil pár compatibility drobností v Kdyby/Facebook a během půl hodinky nám to fungovalo.
V Nette Frameworku funguje instanciování presenterů tak, že v PresenterFactory
se nějak přeloží název presenteru v “Nette tvaru”, třeba Front:Homepage na název třídy, třeba na FrontModule\HomepagePresenter (což závisí na konvenci a jde to samozřejmě změnit).
V tenhle moment známe název třídy, která se má instanciovat a spustit. Jenže tato třída má nějaké závislosti a je potřeba správně vytvořit instanci a tyto závislosti předat. Jak na to? Dříve to fungovalo tak, že se prostě přes reflexi kouklo na konstruktor a proběhl autowire.
Před pár měsíci (nebo roky?) byla přidána podpora pro “vytahování” instancí presenterů z DI Containeru. Což je strašně fajn, protože si pak můžete presentery zaregistrovat do DI Containeru. Analýza závislostí se pak provede compile-time, tedy právě jednou a výkon i čas sežere také právě jednou.
U každé aplikace, která vydělává nějaké peníze, dříve nebo později zjistíte, že potřebujete logovat někam co se děje a co kdo udělal.
Někteří k tomu používají databázi a _audit tabulky, ale ty se nehodí na všechno.
Někdy je prostě jednodušší to nasázet do souborů, a pak už se k nim nikdy nevrátit, protože to nikoho nebaví chodit kontrolovat :)
Ale co si budem, v té databázi by to taky nikdo nekontroloval :)
Kombinaci nástrojů z titulku používáme v DameJidlo.cz i Rohlik.cz a budu ji rozhodně používat všude kde to půjde, pojďme si ukázat proč a jak :)
Pokud právě čtete tento článek, tak jste jistě četli i Eventy a Nette Framework a pokud ne, tak doporučuji si na něj odskočit, já tu počkám.
Jak teď už všichni víme, Eventy jsou strašně silný nástroj, jenže i s Eventy se můžeme dostat do situace, že toho už sice nedělají příliš naše třídy, ale tentokrát celá aplikace. Takové poslání emailu, komunikace s platební bránou, poslání smsky, komunikace s externím pokladním API a kdo ví co ještě nějaký čas zabere.
Nebylo by fajn, kdyby se některé naše eventy zpracovaly asynchronně, na pozadí, abychom nezdržovali uživatele? Tak přesně od toho je RabbitMQ a tedy i Kdyby/RabbitMq.
Nebudu vás ale zatěžovat teorií, tu sepsal už Jakub Kohout i s přehledem několika šikovných nástrojů, které se vám budou hodit. Tak až si to přečtete, pojďme rovnou skočit rovnýma nohama do praxe.
Na Pražské březnové posobotě jsem měl přednášku o Kdyby/Redis, zde jsou slajdy s komentáři:
Kamera byla, takže až to Patrik zpracuje, bude i video
Přednášku jsem si jako vždy připravoval den předem a během přípravy jsem se rozhodl udělat nějaké jednoduché benchmarky. Naprosto mi ale padla čelist, když jsem zjistil že filesystem mám na localhostu rychlejší než RedisStorage. Pojal jsem to statečně a rozhodl se vyzvat publikum, aby mi to pomohlo vyřešit.
Po přednášce jsme měli plodnou diskuzi a kluci se mi vysmáli, že ukládám cache doctrine metadat a annotací do Redisu. Protože používáme nejnovější stable PHP (tedy 5.5.něco) žil jsem v mylné představě že APC je mrtvé a tedy nad tím nemusím vůbec přemýšlet. Jenže! Ono není tak úplně mrtvé a nepoužitelné jak jsem si myslel.
Ještě během Davidovy přednášky jsem nainstaloval APCu, tedy uživatelskou cache z APC (ta část která neztratila smysl existence) a vylepšil Kdyby/Annotations aby na nich šla lépe konfigurovat cache.
Nakonec jsem tedy cache annotací a metadat přesměroval do apcu a místo ~10000 (slovy: deseti tisíců) requestů na prvnotní inicializaci stránky s kompilací containeru a načítání doctrine metadata jsem se dostal na špičkových ~200 requestů do Redisu. Na průměrnou stránku, která už má vygenerovanou cache mi požadavky z původních minimálně 200 spadly na ~80.
Vytížení Redisu víc než o polovinu padlo, aplikace se nepatrně zrychlila a zatím se ani jednou nezasekla na generování cache (což byl předtím problém). Strašák shardování se odkládá na neurčito :)
*PS: Juzno, dlužíš mi ještě to vysvětlení, jak udělat konzistentní hashování klíčů do shardování, které nebude potřeba přehashovávat ani při přidání dalších instancí. Teď to dělám takto
Nad použitím session storage z Kdyby/Redis není třeba vůbec přemýšlet a prostě ji použijte, vyplatí se vždy. A ikdyž je cache malinko pomalejší než jsem doufal (požadavky do 0,3ms na request včetně overheadu mého storage), pořád je brutálně rychlá oproti filesystému pod zátěží.
 {.left-img.tiny-image}
{.left-img.tiny-image}
Před pár měsíci mi www.packtpub.com napsali (jako jednomu z mnoha), jestli bych pro ně nechtěl napsat knihu o Doctrine 2 ORM. Byť o Doctrine něco málo vím, nepřipadal jsem si jako vhodný kandidát, tak jsem to odmítl.
Myslím, že jsem udělal dobře, protože ji nakonec napsal Kévin Dunglas, člověk který přispívá do opensource projektů a ekosystémů jako jsou Symfony, JavaScript a Ubuntu.
Především je opravdu krátká a dá se přečíst za pár hodin (neunudí). Je psaná v angličtině, takže té se rozhodně nevyhnete.
Ve zkratce se dá říct, že kniha Vás naučí Doctrinu od úplných základů a s minimem dalšího studia můžete v pohodě začít psát vlastní, až středně velké aplikace nad Doctrine.
Kniha je opravdu pro úplně začátečníky, pokud jste pokročilý uživatel Doctriny, tak Vám toho nejspíš kniha moc nedá. Já osobně jsem se nedozvěděl nic nového, což je pro mě trochu zklamání, ale dalo se to čekat :)
Stejně tak Vám toho kniha moc nedá pokud máte kompletně pročtenou dokumentaci Doctriny.
Kniha sama o sobě je subset dokumentace. Jenže zatím jsem nepotkal moc lidí, kteří by si poctivě pročetli dokumentaci Doctrine od začátku do konce. Nenavazuje to a bez zkoušení to člověka unudí. Spíše se hodí když si potřebujete dohledat, jak se něco konkrétního dělá.
Celá kniha je jeden dlouhý tutorial, který Vás provede od naprostých základů jako je instalace Composeru
a základy jeho používání, což je například instance balíčku doctrine/orm, až po pokročilá témata jako jsou dědičnost entit nebo systém událostí.
Během čtení knihy doporučuji si vše zkoušet, je to lepší než pak hledat zpětně proč mi něco nefunguje a jako bonus si u toho napíšete jednoduchý blog :)
Knihu je možné koupit na webu www.packtpub.com. Co mě moc potěšilo, tak že si ji můžete stáhnout v PDF a ePUB a ani jedno neobsahuje žádné zjevné DRM. Taky je fajn, že ke knize si můžete stáhnout i všechny ukázky kódu (a funkční).
Mějme tabulku jídel na kterou chceme napsat hledání.
CREATE TABLE `food` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) COLLATE utf8_czech_ci NOT NULL,
`description` text COLLATE utf8_czech_ci NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_czech_ci;
INSERT INTO `food` (`name`, `description`) VALUES
('Semtex', 'energiťák'), ('Čaj', 'heřmánkovej');
Máme dvě možnost, buďto použijeme search engine (ElasticSearch, Sphinx, …) nebo se s tím budeme srát v MySQL. No a aby to bylo zajímavé, tak se s tím pojďme srát :)
První problém, jak ho vyřešit? Triggery.
Takže si vytvoříme tabulku do které budeme duplikovat data (což je v podstatě to stejné co byste dělali s externí službou na hledání)
CREATE TABLE `food_fulltext` (
`food_id` int(11) NOT NULL,
`name` varchar(255) COLLATE utf8_czech_ci NOT NULL,
`description` text COLLATE utf8_czech_ci NOT NULL,
PRIMARY KEY (`food_id`),
FULLTEXT KEY `name_description` (`name`,`description`),
FULLTEXT KEY `name` (`name`),
FULLTEXT KEY `description` (`description`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_czech_ci;
A napíšeme si triggery
DELIMITER ;;
CREATE PROCEDURE `food_fulltext_update` (IN `updated_id` int(11))
BEGIN
DECLARE `name` TEXT ;
DECLARE `description` TEXT ;
SELECT food.`name`, food.`description` INTO `name`, `description`
FROM food WHERE `id` = `updated_id`;
INSERT INTO `food_fulltext` (`food_id`, `name`, `description`) VALUES (`updated_id`, `name`, `description`)
ON DUPLICATE KEY UPDATE `name` = VALUES(`name`), `description` = VALUES(`description`);
END;;
CREATE TRIGGER `food_ai` AFTER INSERT ON `food` FOR EACH ROW
IF @disable_triggers IS NULL THEN
CALL food_fulltext_update(NEW.`id`);
END IF;;
CREATE TRIGGER `food_au` AFTER UPDATE ON `food` FOR EACH ROW
IF @disable_triggers IS NULL THEN
CALL food_fulltext_update(NEW.`id`);
END IF;;
CREATE TRIGGER `food_ad` AFTER DELETE ON `food` FOR EACH ROW
IF @disable_triggers IS NULL THEN
DELETE FROM food_fulltext WHERE `food_id` = OLD.`id`;
END IF;;
DELIMITER ;
INSERT INTO `food_fulltext` (`food_id`, `name`, `description`)
SELECT food.`id`, food.`name`, food.`description` FROM food
Ta proměnná @disable_triggers je vychytávka, aby se daly triggery vypnout při hromadných operacích nad daty.
Trigger může jednoduchý update spomalit klidne i exponenciálně (fakt se to hodí mít možnost vypnout).
Fajn, takže při zápisu do tabulky s jídly se nám data zprelikují pod fulltext a můžeme hned začít s hledáním.
Takhle nějak by mohla vypadat search query (inspirovaná článkem od Jakuba)
SELECT food_id FROM food_fulltext
WHERE MATCH(name, description) AGAINST (? IN BOOLEAN MODE)
ORDER BY 5 * MATCH(name) AGAINST (?) + MATCH(description) AGAINST (?) DESC
LIMIT 1000
a když ji pak proženeme přes Nette\Database\Context
function search($string)
{
$sql = "...";
return $this->db->query($sql, $string, $string, $string)->fetchAll();
}
s hledaným výrazem od uživatele
dump($fulltext->search("Semtex")); // [['food_id' => 1]]
Super, našli jsme Semtex!
Jenže když dáme hledat čaj tak máme problém (konkrétně dva)
dump($fulltext->search("Čaj")); // []
Ten první je, že mysql má výchozí minimální délku slova pro fulltext větší než 3, to se dá změnit celkem snadno
$ sudo nano /etc/mysql/my.cnf
[mysqld]
# Fine Tuning
ft_min_word_len = 3
$ sudo service mysql restart
REPAIR TABLE `food_fulltext` QUICK;
Ten druhý problém je, že dost agresivně zohledňuje diakritiku,
takže na dotaz "Čaj" se nám sice vrátí výsledek, ale na dotaz "caj" se nevrátí nic.
Protože chceme mít proces automatický, abychom nemuseli řešit ukládání do dvou tabulek, tak máme triggery. A protože máme triggery, musíme dělat konverzi na úrovni databáze.
DELIMITER ;;
--
-- https://github.com/falcacibar/mysql-routines-collection/blob/28ef383092ffa5a0e4e7e377fa5d1a3badcc488c/tr.func.sql
-- @author Felipe Alcacibar <[email protected]>
--
CREATE FUNCTION `strtr`(`str` TEXT, `dict_from` VARCHAR(1024), `dict_to` VARCHAR(1024)) RETURNS text LANGUAGE SQL DETERMINISTIC NO SQL SQL SECURITY INVOKER COMMENT ''
BEGIN
DECLARE len INTEGER;
DECLARE i INTEGER;
IF dict_to IS NOT NULL AND (CHAR_LENGTH(dict_from) != CHAR_LENGTH(dict_to)) THEN
SET @error = CONCAT('Length of dicts does not match.');
SIGNAL SQLSTATE '49999'
SET MESSAGE_TEXT = @error;
END IF;
SET len = CHAR_LENGTH(dict_from);
SET i = 1;
WHILE len >= i DO
SET @f = SUBSTR(dict_from, i, 1);
SET @t = IF(dict_to IS NULL, '', SUBSTR(dict_to, i, 1));
SET str = REPLACE(str, @f, @t);
SET i = i + 1;
END WHILE;
RETURN str;
END;;
CREATE FUNCTION `to_ascii`(`str` TEXT) RETURNS text LANGUAGE SQL DETERMINISTIC NO SQL SQL SECURITY INVOKER COMMENT ''
BEGIN
RETURN strtr(LOWER(str), 'áäčďéěëíµňôóöŕřšťúůüýžÁÄČĎÉĚËÍĄŇÓÖÔŘŔŠŤÚŮÜÝŽ', 'aacdeeeilnooorrstuuuyzaacdeeelinooorrstuuuyz');
END;;
Upravíme proceduru která synchronizuje fulltext
DELIMITER ;;
DROP PROCEDURE `food_fulltext_update`;;
CREATE PROCEDURE `food_fulltext_update` (IN `updated_id` int(11))
BEGIN
DECLARE `name` TEXT ;
DECLARE `description` TEXT ;
SELECT to_ascii(food.`name`), to_ascii(food.`description`) INTO `name`, `description`
FROM food WHERE `id` = `updated_id`;
INSERT INTO `food_fulltext` (`food_id`, `name`, `description`) VALUES (`updated_id`, `name`, `description`)
ON DUPLICATE KEY UPDATE `name` = VALUES(`name`), `description` = VALUES(`description`);
END;; -- 0.001 s
A ještě upravíme zpracování vstupu do SQLka
use Nette\Utils\Strings
function search($string)
{
$string = Strings::lower(Strings::normalize($string);
$string = Strings::replace($string, '/[^\d\w]/u', ' ');
$words = Strings::split(Strings::trim($string), '/\s+/u');
$words = array_unique(array_filter($words, function ($word) {
return Strings::length($word) > 1;
}));
$words = array_map(function ($word) {
return Strings::toAscii($word) . '*';
}, $words);
$string = implode(' ', $words);
$sql = "...";
return $this->db->query($sql, $string, $string, $string)->fetchAll();
}
Už jenom otestovat
dump([
$fulltext->search("Čaj"),
$fulltext->search("Caj"),
$fulltext->search("čaj"),
$fulltext->search("caj"),
]); // [['food_id' => 2]], [['food_id' => 2]], [['food_id' => 2]], [['food_id' => 2]]
a máme to hotovo. Doufám že tohle je naposledy co jsem musel řešit fulltext v MySQL a vám to přeji taky ;)
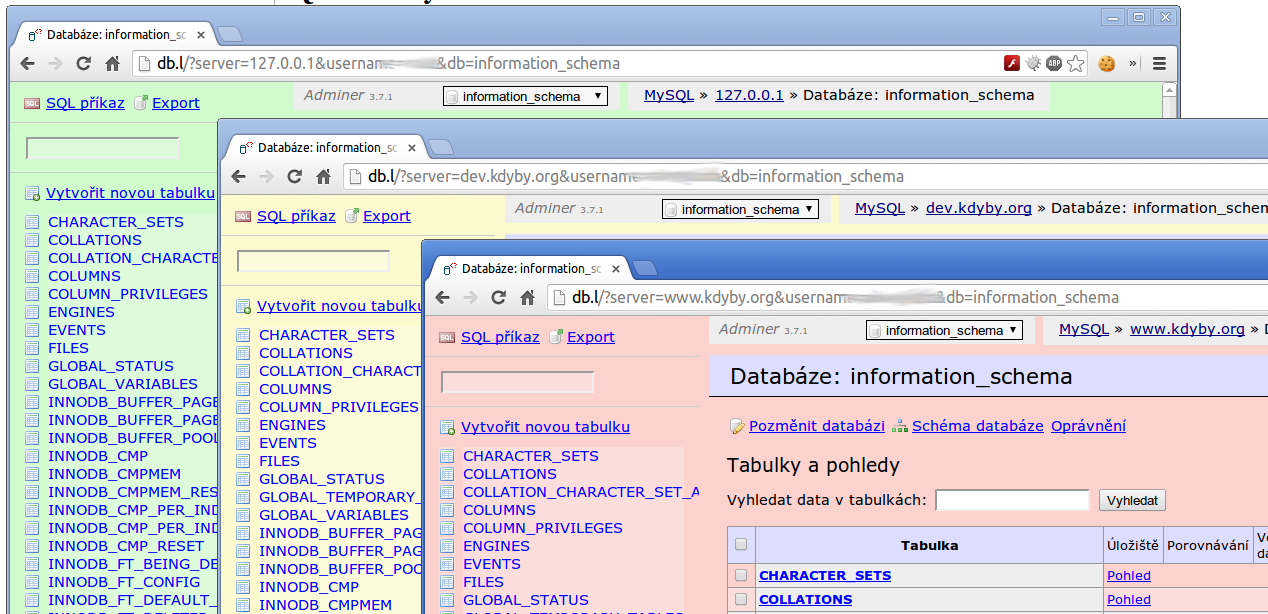
Na desktopových klikátkách na databáze jste už určitě viděli obarvené záložky podle cíle spojení.
Obarvené záložky v Navicatu
Na co je to dobré? No tak například nemusíte číst název spojení a hned víte kde jste. Já barvičky použivám na odlišení “důležitosti” databáze - localhost/dev/produkce.
Jenže nepoužívám Navicat ale Adminer.
adminer-blabla.php na adminer.phpplugins/ a do ní stáhneme soubor plugin.phpindex.php do kterého dáme následující kód a přes který budeme k Admineru přistupovat<?php
function adminer_object()
{
// required to run any plugin
include_once __DIR__ . "/plugins/plugin.php";
// autoloader
foreach (glob("plugins/*.php") as $filename) {
include_once "./$filename";
}
$plugins = array(
// specify enabled plugins here
);
return new AdminerPlugin($plugins);
}
// include original Adminer
include __DIR__ . "/adminer.php";
Tohle je základní kostra. Teď si napíšeme náš plugin.
Psaním tohohle článku jsem strávil více času než psaním následujícího rozšíření, takže to jde pravděpodobně udělat 2x elegantněji a 3x čistěji, ale to mě v tuto chvíli nezajímá, protože je to 10 řádků kódu které doufejme nikdy nebudou řídit žádnou banku :)
Na začátek souboru index.php vložíme následující třídu
class AdminerColors
{
function head()
{
static $colors = array(
// v tomhle poli si můžete zvolit barvy pro jednotlivé adresy
'127.0.0.1' => '#d0fbcd',
'localhost' => '#d0fbcd',
'dev.kdyby.org' => '#fbf9cd',
'www.kdyby.org' => '#fbd2cd',
);
if (!isset($colors[$_GET['server']])) return;
echo '<style>body { background: ' . $colors[$_GET['server']] . '; }</style>';
}
}
A do pole s pluginy vytvoříme novou instanci.
$plugins = array(
new AdminerColors,
);
F5 a localhost už by měl chytnout nezdravou zelenou. Pokud by se vám zdálo, že je to hnusné jak noc, tak máte pravdu. Je to hnus :)
Proto je potřeba stáhnout můj adminer.css (stačí ho umístit do stejné složky jako je index.php a Adminer si ho sám načte), který fixuje ty největší průsery a kdyby se někomu zželelo nás graficky retardovaných programátorů a dodělal by tomu barevnej lifting, vůbec bych se nezlobil :)
Pokud máte stejně jako já záchvaty paranoie a hrůzy z toho, že na produkci omylem smažete sloupeček, tak je tohle ideální řešení pro klidné spaní.
Znáte termín Aspektově orientované programování Stejně jako u “Kdyby/Events”:/blog/eventy-a-nette-framework, pointou je rozbít systém na menší logické celky, ovšem každý přístup to dělá maličko jinak.
Hranice mezi Eventy a AOP je strašlivě tenká a rozhodnout se který přístup v konkrétním případě použít nemusí být vůbec lehké. A aby to náhodou nebylo moc jednoduché, tak Eventy jsou teoreticky nahraditelné AOPčkem, ale naopak to nejde.
AOP má simulovat skládání různých chování (behaviour) do jednoho objektu bez mnohonásobné dědičnosti z venku, aniž by o tom tento objekt věděl. Kdežto událostí je si sám vědom, protože to on je vyvolává, ale už neví o listenerech, které na ně naslouchají.
Používáte rozšíření Kdyby/Events pro Nette Framework? Mám pro vás skvělou zprávu, juzna je používá taky a napsal rozšíření pro PhpStorm, které vám usnadní práci s tímto rozšířením!
Zde si stáhněte rozsíření, které nainstalujete do IDE a můžete ho hned začít používat :)
Má Vaše aplikace víc než pět návštěv denně? Pak není od věci nějakým způsobem monitorovat, co se děje. Za tímhle účelem vznikají nejrůznější placené i opensource řešení. Některé lepší, některé horší. Několik měsíců zpátky jsem řešil, jaký monitoring nasadím na svoje sexy VPS od Wedosu (na kterém běží i tento blog).
@wedoscom Monitoring! To je jediná věc, která mi chybí! Nepotřebuju návštěvnost, ani analytiku - stačí vytíženost zdrojů na VPS.
— Filip Procházka (@ProchazkaFilip) June 18, 2012Nebudu to protahovat, zvolil jsem nakonec NewRelic, který mi poradil Honza Doleček. Jeho jediné mínus je, že je docela drahý. Ale po měsíci trial verze a tričku zdarma už se mi nechtělo nikam migrovat.
Pak jsem dlouho monitoring neřešil a teď máme NewRelic i v Damejidlo.cz. Na své VPS mám pár malých webíků, ale tady už začíná být kritické, mít vše pod dohledem.
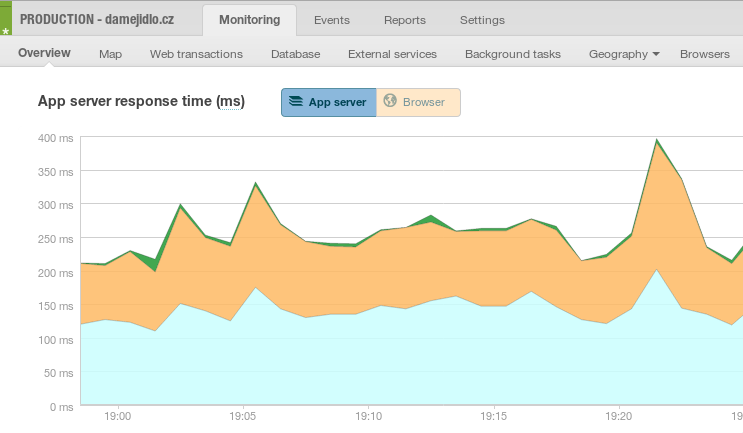
Před pár dny jsem objevil killer feature NewRelicu a o tu bych se s Vámi chtěl zde podělit. Je to jeho PHP API. Abych to trošku rozvedl, NewRelic se instaluje tak, že do phpčka zavedete modul a nastavíte IDčko aplikace. V ten moment začne rozsíření odesílat data na jejich servery a já se můžu kochat krásnými grafy :)
A to prý je Doctrine2 pomalá ;)
Stejným způsobem, prostou instalací balíku, jde rozchodit i monitoring systému.
Náš dev server se moc nenadře :)
a určitě Vám hned dojde jaký, při pohledu na tento screenshot.
NewRelic nerozlišuje adresy, protože všechno jde na index.php
Další “problém” je, že Nette Framework sám řeši všechny chyby a výjimky a NewRelic se tak vůbec v tomto nedostane ke slovu. Když tedy server začne spamovat logy laděnkama, dozvím se to až když mi přijde email, který ani navíc přijít nemusí.
A tady přichází k řeči PHP API, na které mě též upozornil Honza. Chtěl jsem to mít cool, tak jsem řešení založil “na svém Event systému”:/blog/eventy-a-nette-framework.
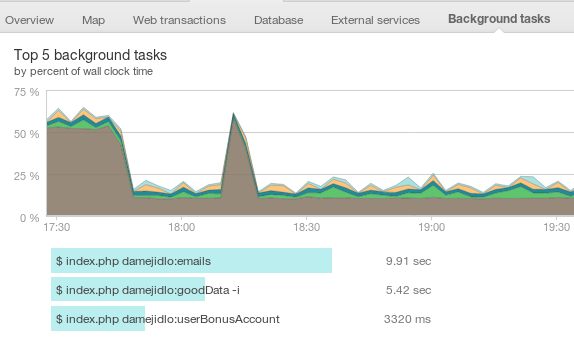
Tohle API pokrývá rozlišení jednotlivých requestů, logování errorů a výjimek a umí taky označit požadavek jako “proces na pozadí”((background job)). Což není špatné rozlišit, protože vydatně používáme CLI scripty přes Symfony Consoli, pouštené cronem a nechceme, aby se nám pletly do frontend requestů. Byť snad všechny zatím roztřídil správně, jistota je jistota :)
Kompletní řešení tedy vypadá takto
namespace NewRelic;
use Kdyby;
use Nette;
use Nette\Application\Application;
use Nette\Application\Request;
use Nette\Diagnostics\Debugger;
class NewRelicProfilingListener extends Nette\Object implements Kdyby\Events\Subscriber
{
public function getSubscribedEvents()
{
return array(
'Nette\\Application\\Application::onStartup',
'Nette\\Application\\Application::onRequest',
'Nette\\Application\\Application::onError'
);
}
public function onStartup(Application $app)
{
if (!extension_loaded('newrelic')) {
return;
}
// registrace vlastního loggeru na errory
Debugger::$logger = new Logger;
Debugger::$logger->directory =& Debugger::$logDirectory;
Debugger::$logger->email =& Debugger::$email;
}
public function onRequest(Application $app, Request $request)
{
if (!extension_loaded('newrelic')) {
return;
}
if (PHP_SAPI === 'cli') {
// uložit v čitelném formátu
newrelic_name_transaction('$ ' . basename($_SERVER['argv'][0]) . ' ' . implode(' ', array_slice($_SERVER['argv'], 1)));
// označit jako proces na pozadí
newrelic_background_job(TRUE);
return;
}
// pojmenování požadavku podle presenteru a akce
$params = $request->getParameters();
newrelic_name_transaction($request->getPresenterName() . (isset($params['action']) ? ':' . $params['action'] : ''));
}
public function onError(Application $app, \Exception $e)
{
if (!extension_loaded('newrelic')) {
return;
}
if ($e instanceof Nette\Application\BadRequestException) {
return; // skip
}
// logovat pouze výjimky, které se dostanou až k uživateli jako chyba 500
newrelic_notice_error($e->getMessage(), $e);
}
}
A ještě Logger
namespace NewRelic;
use Nette;
class Logger extends Nette\Diagnostics\Logger
{
public function log($message, $priority = self::INFO)
{
$res = parent::log($message, $priority);
// pouze zprávy, které jsou označené jako chyby
if ($priority === self::ERROR || $priority === self::CRITICAL) {
if (is_array($message)) {
$message = implode(' ', $message);
}
newrelic_notice_error($message);
}
return $res;
}
}
Pokud máte v aplikaci Kdyby/Events, tak je rozběhání listeneru otázkou tří řádků konfigurace
services:
newRelicListener:
class: NewRelic\NewRelicProfilingListener
tag: [kdyby.subscriber]
Co se týče logování chyb, má NewRelic do laděnky ještě světelné míle daleko. To co tam je teď, připomíná spíše brášku log/error.log. Pro laděnky si tedy stále musím dojít do logu na server. Je ale super vidět prolnutí chybovosti vzhledem k počtu požadavků. Určitě tedy stojí za to, posílat chyby do NewRelicu.
Na druhou stranu, chudý rozbor chyb je vynahrazený luxusním profilerem, který automaticky loguje requesty, které trvají déle než by měly a velice přesně, až možná doterně, upozorňuje na úzká hrdla aplikace.
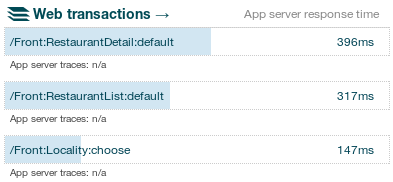
Nyní už uvidím jednotlivé requesty podle presenteru a akce
Requesty seskupené podle presenterů
stejně tak procesy, které probíhají na pozadí
Procesy na pozadí
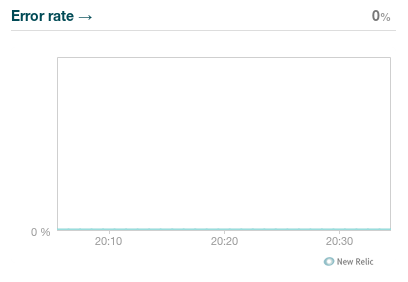
a také všechny chyby, které se v aplikaci vyskytnou.
Procento chyb vzhledem k requestům
Naštěstí jich tam moc není :)
Za mě můžu NewRelic jedině doporučit. U větších aplikací je to must have. Jak monitorujete svoje aplikace vy?
Vyčleňuji právě svoji integraci Doctrine do Nette Frameworku a jedna její část řeší údálosti.
Doctrine má na události jednoduchý systém - existuje třída EventManager, do které se registrují listenery a když se “něco stane”, vyvoláme nad ní událost a ta se předá příslušným listenerům. Pro detaily si můžete odskočit do podrobné dokumentace.
Nette Framework má také události. Používáte je nejspíše každý den ve formulářích, když nastavujete $form->onSuccess[] = $callback;.
A mě napadlo: co kdybych to sjednotil?
(Pro plné pochopení článku je nutné znát použití obou systémů, tak si to skočte přečíst, já tu počkám)
Rozhodl jsem se přepsat všechny svoje testy z PHPUnitu na Nette\Tester a po prvním týdnu mohu s klidným svědomím říct, že se přepisování velice daří a jsem s Testerem spokojený.
Nejprve si nainstalujeme a nastavíme Xdebug, pomocí pecl, který by měl být součastí všech instalací PHP.
$ sudo pecl install xdebug
Dále nás zajímá, odkud bere PHP konfiguraci
$ php -i |grep ini
Configuration File (php.ini) Path => /usr/local/lib
V mém případě složka obsahuje několik .ini souborů
$ ls /usr/local/lib |grep php
php-cli.ini
php-fpm.ini
php.ini
Do všech těchto souborů zkopírujeme následující řádky na úplný konec (většinou jsou nutná root práva).
[xdebug]
zend_extension=xdebug.so
xdebug.remote_enable=1
xdebug.remote_connect_back=On
; xdebug.remote_host=127.0.0.1
; xdebug.remote_port=9001
xdebug.remote_autostart=1
xdebug.remote_log="/var/log/php/xdebug.log"
xdebug.idekey=PHPSTORM
; xdebug.profiler_enable=1
; xdebug.profiler_output_dir=/tmp/xdebug-profiler
Tohle nastaví Xdebug na velice agresivní režim. Na zbytečné rozšíření do prohlížeče (pokud jste nějaké používali) zapomeňte, nejsou potřeba - ukážeme si za moment.
Může se nám také stát, že nějaká aplikace nebo služba bude sedět na portu 9000, který je standardní pro Xdebug - od toho je tu xdebug.remote_port.
Každý operační systém má konfiguraci trošku jinak. Pokud máte Xdebug již nainstalovaný a jste zvyklí ho konfigurovat jinak, tak nejdůležitější jsou tyto volby.
xdebug.remote_enable=1
xdebug.remote_connect_back=On
xdebug.remote_autostart=1
Nezapoměňte restartovat apache, nebo php-fpm ;)
Každý projekt by měl mít nastavený, jakou verzi jazyka používá a cestu k interpreteru.
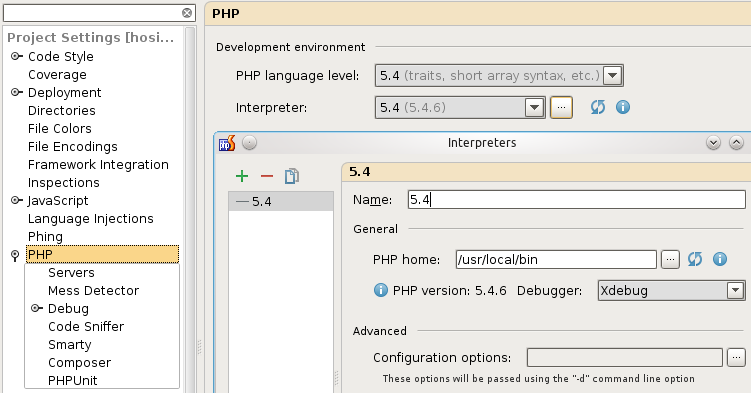
A taky je nutné, aby port souhlasil s nastavením Xdebugu v php.ini. Já používám port 9001, ale 9000 je výchozí a pokud nastavení neměníte, nemusíte tuto nabídku vůbec otevírat.
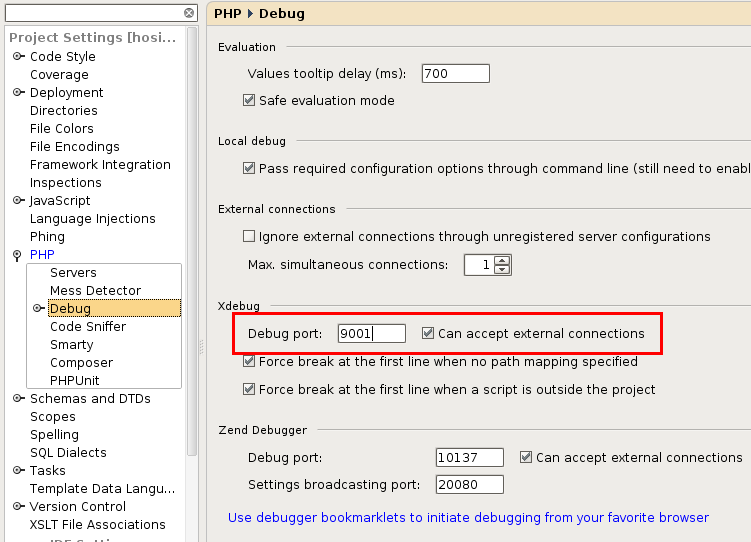
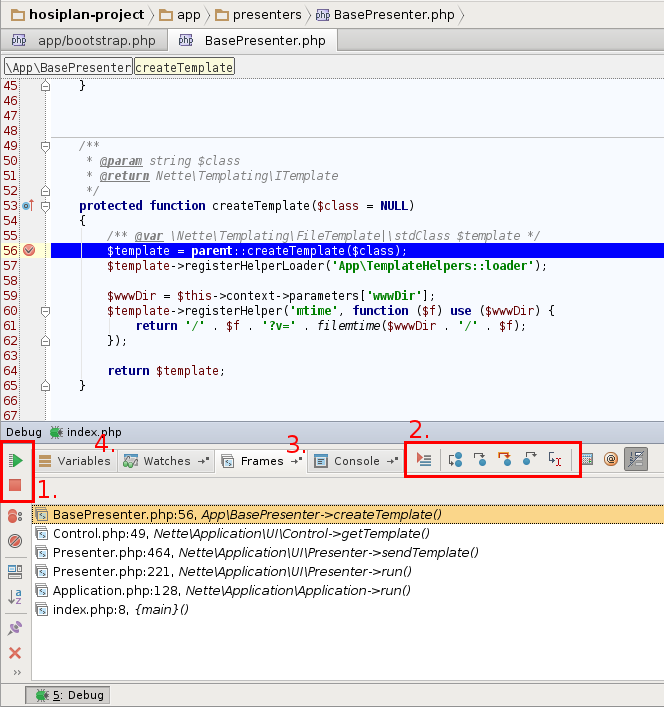
Kliknutím vedle čísla řádku (tam kde je teď červená tečka) vytvoříme tzv. breakpoint. Tj místo, kde se provádění aplikace zastaví a my budeme moct zkoumat stav proměnných a krokovat.
Protože jsme Xdebug nastavili na agresivní mód, tak při úplně každém požadavku bude zkoušet vytvořit spojení. Následující kouzelnou ikonkou řekneme PhpStormu, že má na tato spojení začít přijímat.
Když je telefónek zelený, tak naslouchá. Nevím proč, ale vždycky mě to strašně mate a musím kouknout na titulek…

Nyní stačí otevřít náš projekt v prohlížeči, nebo obnovit stránku.
Poprvé se nás zeptá, jestli má spojení příjmout a pokud mu to povolím, příště se ptát nebude.
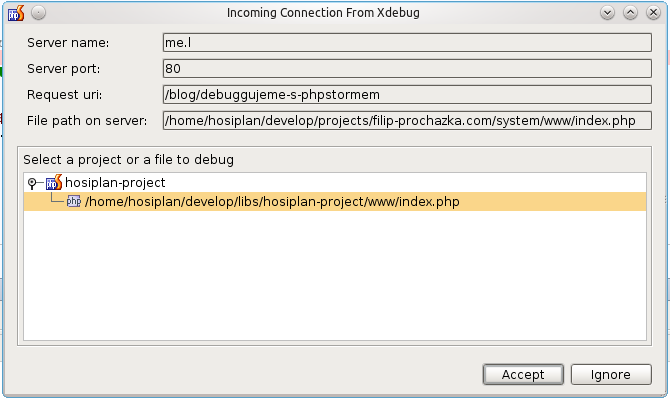
Po spojení se otevře nový panel.
F9 až do konce scriptu, nebo do dalšího breakpointu.F8 - výraz se vykoná, ale “na pozadí””F7 - například když volám nějakou svou funkci, tak debugger krokuje i její obsahShift+F8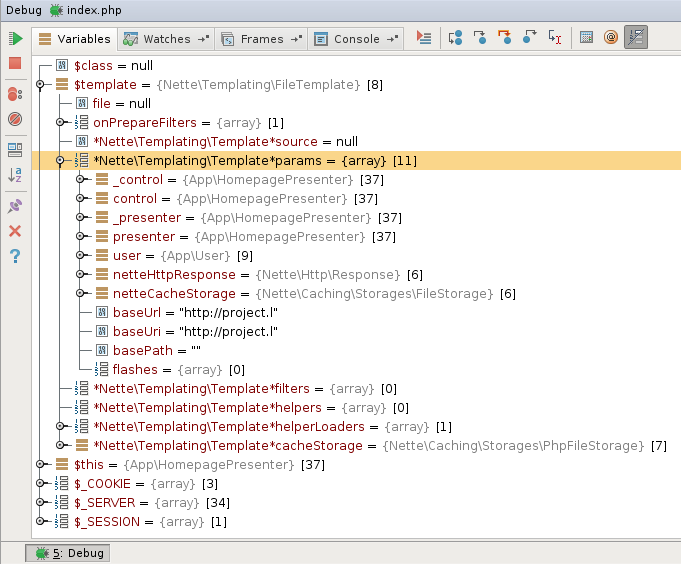
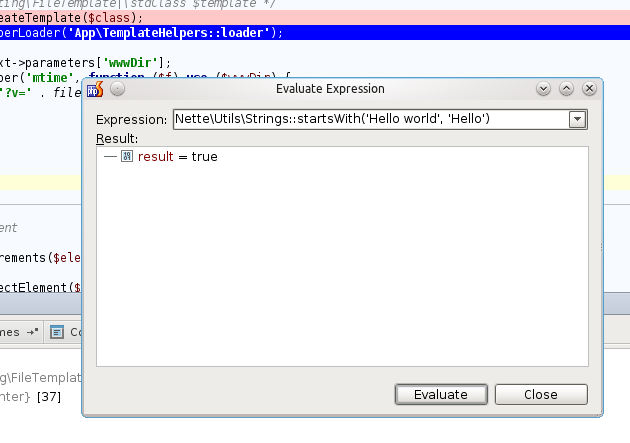
O evalu se říká, že je zlý, ale tento eval je hodný :) Zkratkou ALT+F8 otevřete okno, do kterého můžete psát PHP kód a nechat ho vykonat v aktuálním kontextu scriptu. Velice často si například vložím breakpoint, kde píšu nějaký regulární výraz a ladím ho v tomto okně, dokud mi nevyhovuje jeho výsledek.
Za naprostou killer feature považuji debugování testovacích metod, když si nastavíte dobře PhpUnit.
Vložím do testu breakpoint, pravým tlačítkem hlodavce otevřu nabídku a zvolím “Debug …”
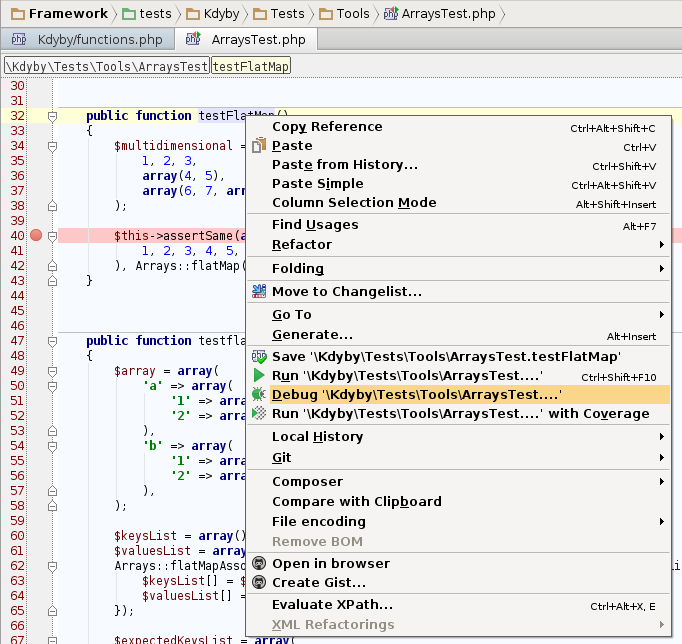
A opět můžu studovat obsah proměnných, měnit jejich hodnoty a volat vlastní funkce.
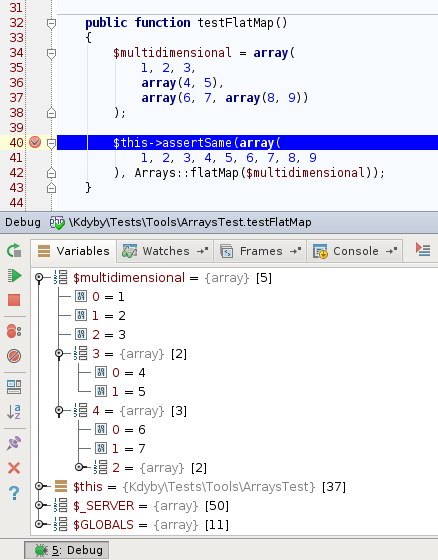
když to co potřebuje je IDE! Sublime text je sice hyper cool textový editor, ve kterém zrovna píšu i tenhle článek, ale přestaňte se už mučit. Kód není text.
PhpStorm můžete používat první měsíc zdarma ;) A pokud se vám nebude líbit, je tu pořád ještě NetBeans a PhpEd.
Composer je skvělý nástroj na správu závislostí pro PHP. A PhpStorm je docela kvalitní (ale hlavně rychlé) IDE. Když se sejdou dva takhle užitečné nástroje, někoho by napadlo, že by mohly spolupracovat.
O nativní podporu Composeru v PhpStormu se již snažíme a s trochou optimismu by to příští Vánoce mohlo být hotové ;) Ale někdo to prostě nevydrží a podporu si přidá sám. Za nápad moc děkuji Vojtěchovi
Přes External Tools jde velice snadno vytvořit klikátka na externí nástroje.
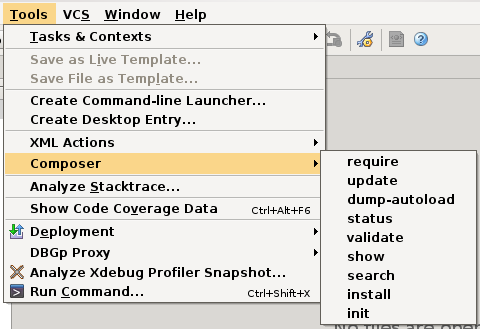
Které jdou spouštět z různých kontextových nabídek
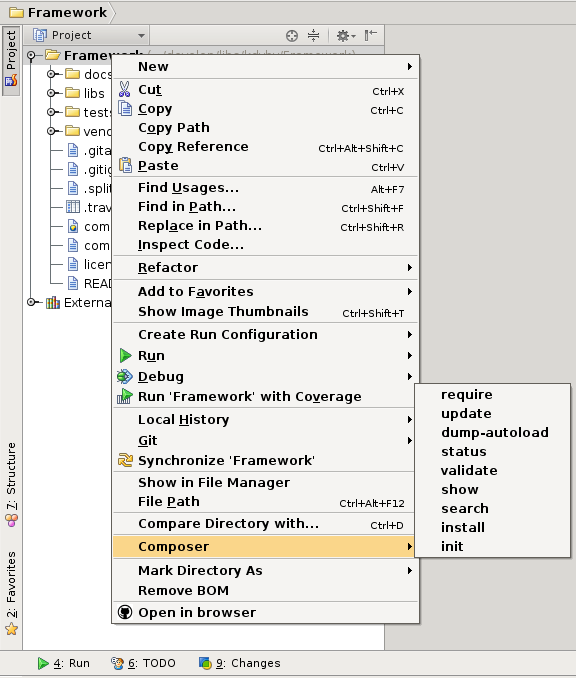
A výsledek operace zobrazí tak jako v konzoli
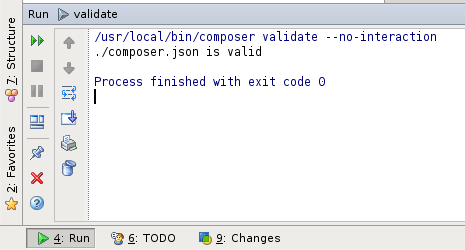
Kde stažení: “phpstorm-tools.jar”:/content/phpstorm-tools.jar (File > Import Settings)
Další zajímavý způsob integrace je použít “Command line tool support”. Více na PhpStorm blogu.
Jaké nástroje máte v PhpStormu (nebo v jiném IDE) podobně integrované vy?
Chcete mít krásný výstup v RSS čtečkách? Já taky!
FSHL generuje do “zvýrazněného” kódu “pouze” css třídy. To má zjevné výhody - stylovat můžete z jednoho místa, v CSS souboru, a ve výsledném kódu pak není zbytečný bordel. Takový obarvený kód je pak na webu krásný, ale v RSS čtečkách už to taková sláva není, protože ty neví co znamenají naše CSS třídy.
Nejprve mě napadlo zkusit posílat i CSS styly, vždy na konci článku. Jenže lenost testovat, jestli to funguje, zvítězila a raději třídy nahrazuji přímo inline stylem.
“Do své entity, která mi představuje článek”((já vím, že to není ideální, ale v systému tohoto blogu je to good-enought místo)), jsem si tedy přidal metodu, která příjme cestu k CSS souboru a všechny CSS třídy z HTML kódu nahradí jejich stylem z předaného souboru.
/** @var array */
private static $languages = array(
'php', 'neon', 'config', 'sh', 'texy', 'js', 'css', 'sql', 'html'
);
/**
* @param string $cssFile
* @return string
*/
public function getRssContent($cssFile = NULL)
{
if (!$cssFile) {
return $this->htmlContent;
}
$cssDefs = file_get_contents($cssFile);
$langs = self::$languages;
return Strings::replace($this->htmlContent, '~class=(?:"|\')?([^"\'>]+)(?:"|\')?~i', function ($class) use ($cssDefs, $langs) {
$style = NULL;
foreach (Strings::split($class[1], '~\s+~') as $class) { // jednotlivé třídy
if (count($parts = explode('-', $class, 2)) !== 2 || !in_array($parts[0], $langs)) {
// pokud třída není ve tvaru "<jazyk>-<klíčové slovo>", tak přeskoč
// pokud jazyk není ve slovníku, tak přeskoč
continue;
}
if ($css = Strings::match($cssDefs, '~.' . preg_quote($class) . '\s*\{([^}]*?)\}~')) {
// nahrazení stylem ze souboru
$style .= Strings::replace($css[1], array('~[\n\r]+~' => '')) . ';';
}
}
return $style ? 'style="' . htmlspecialchars($style, ENT_QUOTES) . '"' : NULL;
});
}
A jak obarvujete kód ve svých RSS vy? :)
Davídek nám ukázal, jak má nastavené texy na https://nette.org, takže jsem toho využil a napsal si nad Texy! vrstvičku.
Stará se o zvýrazňování kódu a taky zpracovává magické “meta makra”.
Potřeboval jsem také, aby do zvárazněného kódu generoval seznamy, tak jako to ve své dokumentaci dělá Twitter Bootstrap, takže jsem povolil ol v elementu pre.
Další požadavek, na kterém jsem se docela zapotil, bylo odstraňování hlavního nadpisu z výsledného kódu a kontrola, jestli obsahuje odkaz. Chci si totiž nadpis renderovat nad článkem zvlášť sám, kvůli tomu, aby se stejný HTML kód dal použít v RSS a nebyl v něm 2x nadpis. Implementace je dost naivní, ale dělám to pro sebe, tak si budu muset pamatovat, že to funguje pouze pokud odkaz obaluje celý obsah nadpisu.
Tohle fungovat bude
"**nadpis**":http://example.com
***
ale tohle už fungovat nebude
**"nadpis":http://example.com**
***
Texy! je nastaveno s vědomím, že výsledek bude na mém blogu - dovolí mi skoro vše.
use Nette\Utils\Html;
use Nette\Utils\Strings;
class Processor extends Nette\Object
{
/** @var \Texy */
private $lastTexy;
/** @var \FSHL\Highlighter */
private $highlighter;
/** @var array */
private $meta = array();
/** @var string */
private $title;
/** @var array */
private static $highlights = array(
'block/code' => TRUE,
'block/php' => 'FSHL\Lexer\Php',
'block/neon' => 'FSHL\Lexer\Neon',
'block/config' => TRUE, // @todo
'block/sh' => TRUE, // @todo
'block/texy' => TRUE, // @todo
'block/javascript' => 'FSHL\Lexer\Javascript',
'block/js' => 'FSHL\Lexer\Javascript',
'block/css' => 'FSHL\Lexer\Css',
'block/sql' => 'FSHL\Lexer\Sql',
'block/html' => 'FSHL\Lexer\Html',
'block/htmlcb' => 'FSHL\Lexer\Html',
);
public function __construct(\FSHL\Highlighter $highlighter)
{
$this->highlighter = $highlighter;
}
public function process($text)
{
$this->meta = array();
$this->title = array('link' => NULL, 'heading' => NULL, 'el' => NULL);
return $this->createTexy()->process($text);
}
public function getMeta()
{
return $this->meta;
}
public function getTitle()
{
return $this->title;
}
public function getLastTexy()
{
return $this->lastTexy;
}
protected function createTexy()
{
$texy = new \Texy();
// obecné nastavení
$texy->allowedTags = \Texy::ALL;
$texy->linkModule->root = '';
$texy->tabWidth = 4;
$texy->phraseModule->tags['phrase/strong'] = 'b';
$texy->phraseModule->tags['phrase/em'] = 'i';
$texy->phraseModule->tags['phrase/em-alt'] = 'i';
// nadpisy
$texy->headingModule->top = 1;
$texy->headingModule->generateID = TRUE;
$texy->addHandler('afterParse', array($this, 'headingHandler'));
// čísla řádků pro twitter bootstrap
$texy->dtd['pre'][1]['ol'] = 1;
// vypne generování bílých znaků ve výsledném kódu,
// aby se neroztahoval kód v elementu <pre>
$texy->htmlOutputModule->indent = FALSE;
// <code>
$texy->addHandler('block', array($this, 'blockHandler'));
// meta
$texy->registerBlockPattern(
array($this, 'metaHandler'),
'#\{\{([^:]+):([^:]+)\}\}$#m', // block patterns must be multiline and line-anchored
'metaBlockSyntax'
);
// return
return $this->lastTexy = $texy;
}
/**
* Metoda vykuchá element hlavního nadpisu z výsledného HTML
* a taky koukne, jeslti nadpis neobsahuje odkaz.
* @internal
*/
public function headingHandler(\Texy $texy, \TexyHtml $DOM, $isSingleLine)
{
list($title) = $texy->headingModule->TOC;
// zkopírovat element
$titleEl = Html::el($title['el']->getName(), $title['el']->attrs);
foreach ($title['el']->getChildren() as $child) {
$titleEl[] = $child;
}
// uklidit
$title['el']->attrs = array();
$title['el']->removeChildren();
$title['el']->setName(NULL);
// parsování odkazu
foreach ($titleEl->getChildren() as $i => $child) {
$matches = Strings::matchAll(
$texy->unProtect($child), // texy magie
'~<([\\w]+)([^>]*?)(([\\s]*\/>)|(>((([^<]*?|<\!\-\-.*?\-\->)|(?R))*)<\/\\1[\s]*>))~sm',
PREG_OFFSET_CAPTURE
);
if (!$matches) break;
list($tag) = $matches;
$titleEl[$i] = $el = Html::el($tag[1][0] . ' ' . $tag[2][0]);
$el->setHtml($tag[6][0]);
if ($el->getName() === 'a') {
$this->title['link'] = $el->attrs['href'];
}
}
// obsah nadpisu
$this->title['heading'] = $titleEl->getText();
$this->title['el'] = $titleEl;
}
/**
* Parsuje meta značky
* @internal
*/
public function metaHandler(\TexyParser $parser, array $matches, $name)
{
list(, $metaName, $metaValue) = $matches;
$this->meta[] = array(
trim(Strings::normalize($metaName)),
trim(Strings::normalize($metaValue))
);
}
/**
* Zýrazňuje kód
* @internal
*/
public function blockHandler(\TexyHandlerInvocation $invocation, $blockType, $content, $lang, $modifier)
{
if (isset(self::$highlights[$blockType])) {
list(, $lang) = explode('/', $blockType);
} else {
return $invocation->proceed($blockType, $content, $lang, $modifier);
}
$texy = $invocation->getTexy();
$content = \Texy::outdent($content);
// zvýraznění syntaxe
if (class_exists($lexerClass = self::$highlights[$blockType])) {
$content = $this->highlighter->highlight($content, new $lexerClass());
} else {
$content = htmlspecialchars($content);
}
$elPre = \TexyHtml::el('pre');
if ($modifier) $modifier->decorate($texy, $elPre);
$elPre->attrs['class'] = 'src-' . strtolower($lang) . ' prettyprint linenums';
// čísla řádků
$elOl = $elPre->create('ol', array('class' => 'linenums'));
foreach (Strings::split($content, '~[\n\r]~') as $i => $line) {
$elLi = $elOl->create('li', array('class' => 'L' . $i));
$elLi->create('span', $texy->protect($line, \Texy::CONTENT_BLOCK));
}
return $elPre;
}
}
Kvůli tomu, že každý řádek nyní obaluji prvkem <li>, je potřeba upravit FSHL, aby se nám nekřížily tagy přes řádek.
class FshlHtmlOutput implements \FSHL\Output
{
private $lastClass = null;
public function template($part, $class)
{
$output = '';
if ($this->lastClass !== $class) {
if (null !== $this->lastClass) $output .= '</span>';
if (null !== $class) $output .= '<span class="' . $class . '">';
$this->lastClass = $class;
}
$part = htmlspecialchars($part, ENT_COMPAT, 'UTF-8');
if ($this->lastClass && strpos($part, "\n") !== FALSE) {
$endline = "</span>\n" . '<span class="' . $this->lastClass . '">';
$part = str_replace("\n", $endline, $part);
}
return $output . $part;
}
public function keyword($part, $class)
{
$output = '';
if ($this->lastClass !== $class) {
if (null !== $this->lastClass) $output .= '</span>';
if (null !== $class) $output .= '<span class="' . $class . '">';
$this->lastClass = $class;
}
return $output . htmlspecialchars($part, ENT_COMPAT, 'UTF-8');
}
}
Výsledný Processor pak používám následovně
$processor = new Processor(new FSHL\Highlighter(new FshlHtmlOutput()));
$html = $processor->process($texy);
$meta = $processor->meta;
Byl jsem krapet v šoku, když jsem zjistil, že tento krásný blok s kódem není ve standardní distribuci Twitter Bootstrap. Kdo je líný kuchat to z jejich webu, tak CSS je zde:
.prettyprint {
padding: 8px; background-color: #f7f7f9; border: 1px solid #e1e1e8;
}
.prettyprint.linenums {
-webkit-box-shadow: inset 45px 0 0 #fbfbfc, inset 46px 0 0 #ececf0;
-moz-box-shadow: inset 45px 0 0 #fbfbfc, inset 46px 0 0 #ececf0;
box-shadow: inset 45px 0 0 #fbfbfc, inset 46px 0 0 #ececf0;
}
ol.linenums {
margin: 0 0 0 43px; /* IE indents via margin-left */
}
ol.linenums li {
padding-left: 6px; color: #bebec5; line-height: 20px; text-shadow: 0 1px 0 #fff;
}
ol.linenums li > span {
color: black;
}